
Introducing mle-hyperopt: A Lightweight Tool for Hyperparameter Optimization 🚂
Published:
Validating a simulation across a large range of parameters or tuning the hyperparameters of a neural network is common practice for every computational scientist. There are a plethora of open source tools that implement individual algorithms, but many of them are either combersome to set up and log or follow diverse syntax, which makes it hard to easily wrap them. For my personal research setup I wanted a simple API that allows me to generate batches of parameter configurations for various types of experiments and that comes with a set of handy features. These included the following:
- API simplicity: The
mle-hyperoptuses a simple interface alástrategy.ask()andstrategy.tell(). Furthermore, many of the search spaces can be exported and repurposed. E.g. if you want to autovectorize/jax.vmapover a grid of parameters. - Strategy diversity: While most hyperparameter tools implement the newest population-based search algorithms and Bayesian Optimization variants, often times they do not feature simple grid search. Even though Bergstra and Bengio (2012) showed that random search can be more efficient, often an intuitive understanding of a grey-box model can be enhanced by semi-exhaustive evaluation.
- Interactive search space refinement: After a certain set of search iterations, it can make sense to refine your search space boundaries based on the top performing configurations. This way the search can focus on a smaller range of promising configurations. This was for example done in Schmidt et al. (2021) and significantly improve computation efficient resource allocation.
- Exporting of configuration files: Often times I want to submit a batch of training runs to a compute cluster (Slurm, etc.) and need to execute a downstream training routine that looks somewhat as follows:
python train.py --config_fname config.yaml. In that case it is useful to have one script that executes calls to the cluster scheduler after having generated the configurations. - Storage and reloading of previous search logs: I was astonished by how few libraries provide the simple utility of exporting and importing a previous search experiment for later continuation. E.g., in order to accomplish something similar in the FAIR’s awesome nevergrad library, one has to write manual functionality that dumps the search log, reloads and supplies the previously stored results to a new search strategy instance.
And this was how the mle-hyperopt package was born. [Note: I by no means claim that this is something novel. Most likely you may your own substitute tool. But maybe you find a couple of the package’s features useful. So hang in there 🤗] As of writing the package includes a set of diverse (e.g. single vs. multi-objective, model-free vs. model-based) search algorithms:
| Search Type | Description | search_config |
|
|---|---|---|---|
 |
GridSearch |
Search over list of discrete values | - |
 |
RandomSearch |
Random search over variable ranges | refine_after, refine_top_k |
 |
CoordinateSearch |
Coordinate-wise optim. with defaults | order, defaults |
 |
SMBOSearch |
Sequential model-based optim. | base_estimator, acq_function, n_initial_points |
 |
NevergradSearch |
Multi-objective nevergrad wrapper | optimizer, budget_size, num_workers |
Each strategy implements a separate search space which one can sample from. The API follows the standard ask, eval, tell paradigm. The general package structure is summarized as follows:
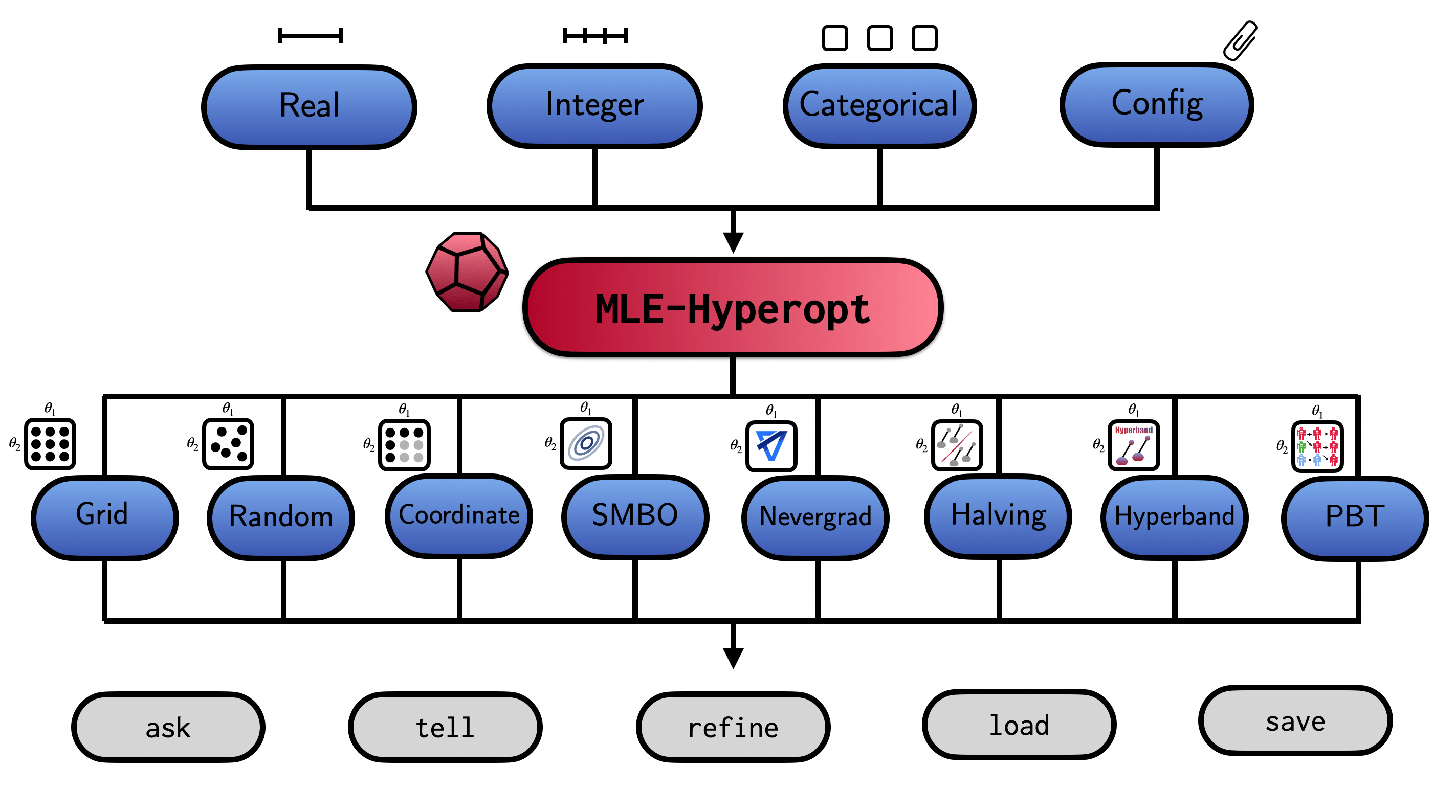
![]()

In the remainder of this ‘blog notebook’ we will walk through the different features and use-cases. Let’s start by implementing a small ‘synthetic’ helper function that evaluates the performance of a combination of 3 standard hyperparameters – learning rate, batchsize and architecture:
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = 'retina'
try:
import mle_hyperopt
except:
!pip install -q mle-hyperopt
import mle_hyperopt
def fake_train(lrate, batch_size, arch):
"""Optimum: lrate=0.2, batch_size=4, arch='conv'."""
f1 = ((lrate - 0.2) ** 2 + ((batch_size - 4)/4) ** 2
+ (0 if arch == "conv" else 0.2))
return f1
Basic API Usage: Grid Search
Imagine you simply want to loop over a discretized range of hyperparameters for our training surrogate. In order to do so we first need to define the search space. The mle-hyperopt package supports real-, integer- and categorically-valued parameters, whose ranges you specify via dictionaries. For real variables and integers you have to specifiy the beginning and end of the range (begin/end) as well as a prior (e.g. uniform or log-uniform) or the number of bins to discretize (prior/bins). For categorical variables simply supply a list of values:
| Variable | Type | Space Specification | |
|---|---|---|---|
 |
real |
Real-valued | Dict: begin, end, prior/bins (grid) |
 |
integer |
Integer-valued | Dict: begin, end, prior/bins (grid) |
 |
categorical |
Categorical | List: Values to search over |
Let’s now instantiate of search strategy for a range of learning rates and batch sizes as well as two network types we want to evaluate:
from mle_hyperopt import GridSearch
# Instantiate grid search class
strategy = GridSearch(real={"lrate": {"begin": 0.1,
"end": 0.5,
"bins": 5}},
integer={"batch_size": {"begin": 1,
"end": 5,
"bins": 1}},
categorical={"arch": ["mlp", "cnn"]},
verbose=True)
MLE-Hyperopt Gird Search Hyperspace 🚀 🌻 Variable Type Search Range ↔ ─────────────────────────────────────────────────────────── arch categorical ['mlp', 'cnn'] lrate real Begin: 0.1, End: 0.5, Bins: 5 batch_size integer Begin: 1, End: 5, Bins: 1
If you set the verbosity option, the logged data will be printed to your console using the beautiful rich package. We are now ready to ask our search strategy for a set of proposal candidates:
# Ask the strategy for five configs to evaluate
configs = strategy.ask(batch_size=5)
configs
[{'arch': 'mlp', 'batch_size': 1, 'lrate': 0.1},
{'arch': 'mlp', 'batch_size': 1, 'lrate': 0.2},
{'arch': 'mlp', 'batch_size': 1, 'lrate': 0.30000000000000004},
{'arch': 'mlp', 'batch_size': 1, 'lrate': 0.4},
{'arch': 'mlp', 'batch_size': 1, 'lrate': 0.5}]
Next, we can quickly evaluate our fake surrogate objective for the two proposal configurations and afterwards update the strategy with the collected data (e.g. a validation score). Note that the API assumes that we are minimizing an objective. If you want to instead maximize simply provide the option maximize_objective = True when instantiating the search strategy.
# Simple ask - eval - tell API
values = [fake_train(**c) for c in configs]
strategy.tell(configs, values)
┏━━━━━━━━━━━━━━━┳━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ 📥 Total: 5 ┃ ID ┃ Obj. 📉 ┃ Configuration 🔖 - 10/23/2021 20:55:21 ┃ ┡━━━━━━━━━━━━━━━╇━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ Best Overall │ 1 │ 0.762 │ 'arch': 'mlp', 'batch_size': 1, 'lrate': 0.2 │ │ Best in Batch │ 1 │ 0.762 │ 'arch': 'mlp', 'batch_size': 1, 'lrate': 0.2 │ └───────────────┴────┴─────────┴──────────────────────────────────────────────┘
The log can be stored and reloaded using strategy.save() and strategy.load():
# Storing of results to .pkl
strategy.save("search_log.json")
# Reloading of results from .pkl
strategy.load("search_log.json")
[20:55:21] {'arch': 'mlp', 'batch_size': 1, 'lrate': 0.1} was previously search.py:133 evaluated.
[20:55:21] {'arch': 'mlp', 'batch_size': 1, 'lrate': 0.2} was previously search.py:133 evaluated.
[20:55:21] {'arch': 'mlp', 'batch_size': 1, 'lrate': 0.30000000000000004} was search.py:133 previously evaluated.
[20:55:21] {'arch': 'mlp', 'batch_size': 1, 'lrate': 0.4} was previously search.py:133 evaluated.
[20:55:21] {'arch': 'mlp', 'batch_size': 1, 'lrate': 0.5} was previously search.py:133 evaluated.
[20:55:21] Reloaded 0 previous search iterations. search.py:196
Note that no configuration is added to the log since they were already previously archived. This is different if we instatiate a new strategy with the reload_path option. In this case the new search strategy will load the previously stored log from the json file:
strategy = GridSearch(real={"lrate": {"begin": 0.1,
"end": 0.5,
"bins": 5}},
integer={"batch_size": {"begin": 1,
"end": 5,
"bins": 1}},
categorical={"arch": ["mlp", "cnn"]},
reload_path="search_log.json")
[20:55:21] Reloaded 5 previous search iterations. search.py:196
There are different ways how you can access and analyse the search results:
strategy.logwill return the raw internal list of evaluation results.strategy.to_df()will return the flattened log as a pandas dataframe.strategy.get_best(top_k)will retrieve thetop_kbest performing configurations.
But my two favorite tools are a plot of the best performance over search iterations and the overall ranking:
# Plot timeseries of best performing score over search iterations
strategy.plot_best()
(<Figure size 432x288 with 1 Axes>,
<AxesSubplot:title={'center':'Best Objective Value'}, xlabel='# Config Evaluations', ylabel='Objective'>)

# Print out ranking of best performers
strategy.print_ranking(top_k=4)
┏━━━━━━━━━┳━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ 🥇 Rank ┃ ID ┃ Obj. 📉 ┃ Configuration 🔖 ┃
┡━━━━━━━━━╇━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ 1 │ 1 │ 0.762 │ 'arch': 'mlp', 'batch_size': 1, 'lrate': 0.2 │
│ 2 │ 0 │ 0.772 │ 'arch': 'mlp', 'batch_size': 1, 'lrate': 0.1 │
│ 3 │ 2 │ 0.772 │ 'arch': 'mlp', 'batch_size': 1, 'lrate': 0.3 │
│ 4 │ 3 │ 0.802 │ 'arch': 'mlp', 'batch_size': 1, 'lrate': 0.4 │
└─────────┴────┴─────────┴──────────────────────────────────────────────┘
In case you don’t want to search over all configuration parameters, you can also add a dictionary of fixed parameters at instantiation (fixed_params). Additionally, you can also directly store the configurations as files by setting store=True (or also provide the filenames as a list using the config_fnames option). Below is an example for the case where we want to add a momentum parameter with value 0.9 to all configurations:
strategy = GridSearch(real={"lrate": {"begin": 0.1,
"end": 0.5,
"bins": 5}},
integer={"batch_size": {"begin": 1,
"end": 5,
"bins": 1}},
categorical={"arch": ["mlp", "cnn"]},
fixed_params={"momentum": 0.9})
strategy.ask(2, store=True)
([{'arch': 'mlp', 'batch_size': 1, 'lrate': 0.1, 'momentum': 0.9},
{'arch': 'mlp', 'batch_size': 1, 'lrate': 0.2, 'momentum': 0.9}],
['eval_0.yaml', 'eval_1.yaml'])
Random Search & Search Space Refinement
Next let’s see how we can define a random search strategy with priors over variables. As before we will define our search space using a set of dictionaries, but now the real and integer parameters will have a uniform or log-uniform prior placed over their range:
from mle_hyperopt import RandomSearch
strategy = RandomSearch(real={"lrate": {"begin": 0.1,
"end": 0.5,
"prior": "uniform"}},
integer={"batch_size": {"begin": 1,
"end": 5,
"prior": "log-uniform"}},
categorical={"arch": ["mlp", "cnn"]},
search_config={"refine_after": 5,
"refine_top_k": 2},
seed_id=42,
verbose=True)
configs = strategy.ask(5)
values = [fake_train(**c) for c in configs]
strategy.tell(configs, values)
MLE-Hyperopt Random Search Hyperspace 🚀 🌻 Variable Type Search Range ↔ ────────────────────────────────────────────────────────────────── arch categorical ['mlp', 'cnn'] lrate real Begin: 0.1, End: 0.5, Prior: uniform batch_size integer Begin: 1, End: 5, Prior: log-uniform
┏━━━━━━━━━━━━━━━┳━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ 📥 Total: 5 ┃ ID ┃ Obj. 📉 ┃ Configuration 🔖 - 10/23/2021 20:55:22 ┃ ┡━━━━━━━━━━━━━━━╇━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ Best Overall │ 4 │ 0.268 │ 'arch': 'cnn', 'lrate': 0.123, 'batch_size': │ │ │ │ │ 3 │ │ Best in Batch │ 4 │ 0.268 │ 'arch': 'cnn', 'lrate': 0.123, 'batch_size': │ │ │ │ │ 3 │ └───────────────┴────┴─────────┴───────────────────────────────────────────────┘
MLE-Hyperopt Random Search - 5 Evals - Top 2 - Refined Hyperspace 🚀 🌻 Variable Type Search Range ↔ ────────────────────────────────────────────────────────────────────────────── arch categorical ['mlp', 'cnn'] lrate real Begin: 0.123, End: 0.34044600469728353, Prior: uniform batch_size integer Begin: 3, End: 3, Prior: log-uniform
In the random search instantiation above we have additionally set the random seed for reproducibility and supplied a search_config dictionary with two keys: refine_after and refine_top_k. These two define when and how the search space will be contracted. More specifically, the ranges and categorical values will be altered to only include those of the top-k best performing configurations stored in the strategy log. This allows the strategy to spend more time sampling from regions of the search space, which have proven well-performing.
SMBO & Coordinate-Wise Search
The mle-hyperopt package also wraps around the scikit-optimize API and provides a simple interface for SMBO (Hutter et al., 2011). You can customize the optimizer object with the search_config options. This includes different surrogate models (“GP”, “RF”, “ET”, “GBRT”) and acquisition functions (“LCB”, “EI”, “PI”) as well as random initial seeding configurations. For more information check out the scikit optimizer documentation.
from mle_hyperopt import SMBOSearch
strategy = SMBOSearch(real={"lrate": {"begin": 0.1,
"end": 0.5,
"prior": "uniform"}},
integer={"batch_size": {"begin": 1,
"end": 5,
"prior": "uniform"}},
search_config={"base_estimator": "GP",
"acq_function": "gp_hedge",
"n_initial_points": 5},
fixed_params={"arch": "cnn"})
configs = strategy.ask(5)
values = [fake_train(**c) for c in configs]
strategy.tell(configs, values)
Furthermore, I also implemented a more heuristic search, which I often would implement manually: We start by scanning one parameter and hold the other considered parameters fixed to a pre-specified defaults value. Afterwards, the previously scanned parameter is in turn fixed to its best value and we go over to the next parameter. We repeat this coordinate-wise search until all specified parameters are completed. The order in which we search over the variables is specified in the search_config.
from mle_hyperopt import CoordinateSearch
strategy = CoordinateSearch(real={"lrate": {"begin": 0.1,
"end": 0.5,
"bins": 5}},
integer={"batch_size": {"begin": 1,
"end": 5,
"bins": 5}},
categorical={"arch": ["mlp", "cnn"]},
search_config={"order": ["lrate", "batch_size", "arch"],
"defaults": {"lrate": 0.1,
"batch_size": 3,
"arch": "mlp"}},
verbose=True)
configs = strategy.ask(5)
configs
[20:55:22] New active variable `lrate`. coordinate.py:114
MLE-Hyperopt Coordinate-Wise Search Hyperspace 🚀 🌻 Variable Type Search Range ↔ ─────────────────────────────────────────────────────────── batch_size categorical [3] arch categorical ['mlp'] lrate real Begin: 0.1, End: 0.5, Bins: 5
[{'arch': 'mlp', 'batch_size': 3, 'lrate': 0.1},
{'arch': 'mlp', 'batch_size': 3, 'lrate': 0.2},
{'arch': 'mlp', 'batch_size': 3, 'lrate': 0.30000000000000004},
{'arch': 'mlp', 'batch_size': 3, 'lrate': 0.4},
{'arch': 'mlp', 'batch_size': 3, 'lrate': 0.5}]
values = [fake_train(**c) for c in configs]
strategy.tell(configs, values)
[20:55:22] Fixed `lrate` hyperparameter to 0.2. coordinate.py:109
[20:55:22] New active variable `batch_size`. coordinate.py:114
┏━━━━━━━━━━━━━━━┳━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ 📥 Total: 5 ┃ ID ┃ Obj. 📉 ┃ Configuration 🔖 - 10/23/2021 20:55:22 ┃ ┡━━━━━━━━━━━━━━━╇━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ Best Overall │ 1 │ 0.263 │ 'arch': 'mlp', 'batch_size': 3, 'lrate': 0.2 │ │ Best in Batch │ 1 │ 0.263 │ 'arch': 'mlp', 'batch_size': 3, 'lrate': 0.2 │ └───────────────┴────┴─────────┴──────────────────────────────────────────────┘
configs = strategy.ask(4)
values = [fake_train(**c) for c in configs]
strategy.tell(configs, values)
[20:55:22] Fixed `batch_size` hyperparameter to 4. coordinate.py:109
[20:55:22] New active variable `arch`. coordinate.py:114
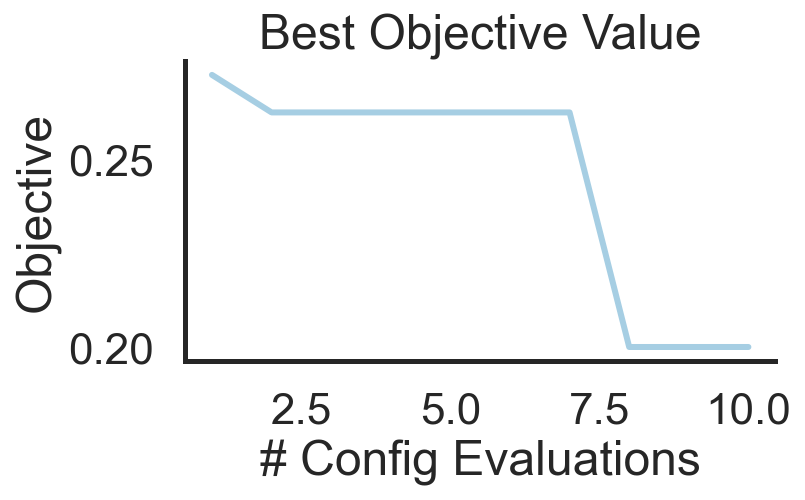
┏━━━━━━━━━━━━━━━┳━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ 📥 Total: 9 ┃ ID ┃ Obj. 📉 ┃ Configuration 🔖 - 10/23/2021 20:55:22 ┃ ┡━━━━━━━━━━━━━━━╇━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ Best Overall │ 7 │ 0.2 │ 'arch': 'mlp', 'batch_size': 4, 'lrate': 0.2 │ │ Best in Batch │ 7 │ 0.2 │ 'arch': 'mlp', 'batch_size': 4, 'lrate': 0.2 │ └───────────────┴────┴─────────┴──────────────────────────────────────────────┘
configs = strategy.ask()
values = fake_train(**configs)
strategy.tell(configs, values)
┏━━━━━━━━━━━━━━━┳━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ 📥 Total: 10 ┃ ID ┃ Obj. 📉 ┃ Configuration 🔖 - 10/23/2021 20:55:22 ┃ ┡━━━━━━━━━━━━━━━╇━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ Best Overall │ 7 │ 0.2 │ 'arch': 'mlp', 'batch_size': 4, 'lrate': 0.2 │ │ Best in Batch │ 9 │ 0.2 │ 'arch': 'cnn', 'batch_size': 4, 'lrate': 0.2 │ └───────────────┴────┴─────────┴──────────────────────────────────────────────┘
strategy.plot_best()
(<Figure size 432x288 with 1 Axes>,
<AxesSubplot:title={'center':'Best Objective Value'}, xlabel='# Config Evaluations', ylabel='Objective'>)
Multi-Objective Hyperparameter Optimization with nevergrad
So far we have discussed a set of single objective hyperparameter search strategies. But how about cases where we are interested in more than one objective? E.g. test accuracy and inference time. For these cases and for even more diverse search strategies we wrap around the nevergrad library by Facebook Research.
def multi_fake_train(lrate, batch_size, arch):
# optimal for learning_rate=0.2, batch_size=4, architecture="conv"
f1 = ((lrate - 0.2) ** 2 + (batch_size - 4) ** 2
+ (0 if arch == "conv" else 10))
# optimal for learning_rate=0.3, batch_size=2, architecture="mlp"
f2 = ((lrate - 0.3) ** 2 + (batch_size - 2) ** 2
+ (0 if arch == "mlp" else 5))
return f1, f2
from mle_hyperopt import NevergradSearch
strategy = NevergradSearch(real={"lrate": {"begin": 0.1,
"end": 0.5,
"prior": "uniform"}},
integer={"batch_size": {"begin": 1,
"end": 5,
"prior": "uniform"}},
search_config={"optimizer": "NGOpt",
"budget_size": 100,
"num_workers": 5},
fixed_params={"arch": "cnn"})
configs = strategy.ask(5)
values = [multi_fake_train(**c) for c in configs]
strategy.tell(configs, values)
strategy.log
[{'eval_id': 0,
'params': {'lrate': 0.2895155928359631, 'batch_size': 4},
'objective': (10.008013041360774, 9.00010992279358)},
{'eval_id': 1,
'params': {'lrate': 0.27813231046267645, 'batch_size': 2},
'objective': (14.006104657938236, 5.000478195845701)},
{'eval_id': 2,
'params': {'lrate': 0.16412518606830023, 'batch_size': 2},
'objective': (14.001287002274633, 5.018461965060974)},
{'eval_id': 3,
'params': {'lrate': 0.3172378807360612, 'batch_size': 3},
'objective': (11.013744720679483, 6.00029714453227)},
{'eval_id': 4,
'params': {'lrate': 0.28916633667720637, 'batch_size': 4},
'objective': (10.007950635596433, 9.000117368260991)}]
strategy.print_ranking()
┏━━━━━━━━━┳━━━━┳━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ 🥇 Rank ┃ ID ┃ Obj. 📉 ┃ Configuration 🔖 ┃
┡━━━━━━━━━╇━━━━╇━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ 1 │ - │ [10.008, 9.0] │ 'lrate': 0.289, 'batch_size': 4 │
│ 2 │ - │ [10.008, 9.0] │ 'lrate': 0.29, 'batch_size': 4 │
│ 3 │ - │ [11.014, 6.0] │ 'lrate': 0.317, 'batch_size': 3 │
│ 4 │ - │ [14.001, 5.018] │ 'lrate': 0.164, 'batch_size': 2 │
│ 5 │ - │ [14.006, 5.0] │ 'lrate': 0.278, 'batch_size': 2 │
└─────────┴────┴─────────────────┴─────────────────────────────────┘
hyperopt decorator - minimal search wrapper
For convenience I also added a simple hyperopt function decorator, which allows you to automatically execute the search procedure loop. The decorator assumes that the function to evaluate directly consumes a configuration dictionary:
from mle_hyperopt import hyperopt
@hyperopt(strategy_type="grid",
num_search_iters=400,
real={"x": {"begin": -0.5, "end": 0.5, "bins": 20},
"y": {"begin": -0.5, "end": 0.5, "bins": 20}})
def circle_objective(config):
distance = abs((config["x"] ** 2 + config["y"] ** 2))
return distance
strategy = circle_objective()
len(strategy)
400
Additionally you can plot the results of any grid search as follows:
strategy.plot_grid(params_to_plot=["x", "y"],
target_to_plot="objective",
plot_title="Circles for Life",
plot_subtitle="How beautiful can they be?",
xy_labels= ["x", "y"],
variable_name="Objective Name",
every_nth_tick=3)
(<Figure size 720x576 with 2 Axes>,
<AxesSubplot:title={'center':'Circles for Life\nHow beautiful can they be?'}, xlabel='x', ylabel='y'>)

If there are more than two search variables please additionally provide a fixed_params dictionary specifying the variable name and value to fix it to in the plot.
Integration with mle-logging 
try:
from mle_logging import MLELogger
except:
!pip install -q mle-logging
from mle_logging import MLELogger
Finally, the mle-hyperopt package also smoothly integrates with my mle-logging package, which I leverage to log training statistics, checkpoints and other objects of interest. You can simply store the configurations and provide the configuration filename as an input to the MLELogger. The logger will then load the configuration and copy it to the logging directory:
# Store a set of configurations
strategy = GridSearch(real={"lrate": {"begin": 0.1, "end": 0.5, "bins": 5}})
config, config_fname = strategy.ask(store=True)
# Instantiate logging to experiment_dir & pass configuration path
log = MLELogger(time_to_track=['num_updates', 'num_epochs'],
what_to_track=['train_loss', 'test_loss'],
experiment_dir="experiment_dir/",
config_fname=config_fname,
use_tboard=False,
model_type='torch')
# Check loaded and copied configuration
log.config_dict
{'lrate': 0.1}
Give it a try and let me know what you think! If you find a bug or are missing your favourite feature, feel free to contact me @RobertTLange or create an issue!